线性回归模型和最小二乘法¶
1 线性回归模型¶
-
形式:
-
变量 可以有下列不同的来源(无论 是哪个来源,模型关于参数都是线性的)
-
定量的输入变量
- 定量输入变量的变换,比如对数变换,平方根变换或者平方变换
- 基函数展开,比如
- 定性输入变量水平 (level) 的数值或“虚拟”编码
- 比如有5种水平,若,可以构造
-
变量的交叉影响,比如
-
什么是线性模型
-
统计意义:若一个回归等式是线性的,其参数就必须也是线性的。对于参数是线性,即使样本变量的特征(属性)是二次方或者多次方,这个回归模型也是线性的。
-
线性和非线性的区别是是否可以用直线将样本划分开:线性模型可以是用曲线拟合样本,但是分类的决策边界一定是直线的,例如logistics模型。
-
如何区分:
- 若每个参数都只影响一个,则是线性的;否则是非线性
- 例如
- 线性:
- 非线性:
2 最小二乘法¶
2.1 公式推导¶
-
残差平方和
-
求解
2.2 最小二乘估计的几何表示¶
-
记 的列向量为 ,其中 。这些向量张成了 的子空间,也被称作 的列空间。
-
当列满秩,可逆(证明见子空间与投影矩阵),则由公式 , 可以看出与的列向量均正交
- 由于,所以是在子空间中的投影
- 同时也可以得出投影是到欧氏距离最近的点
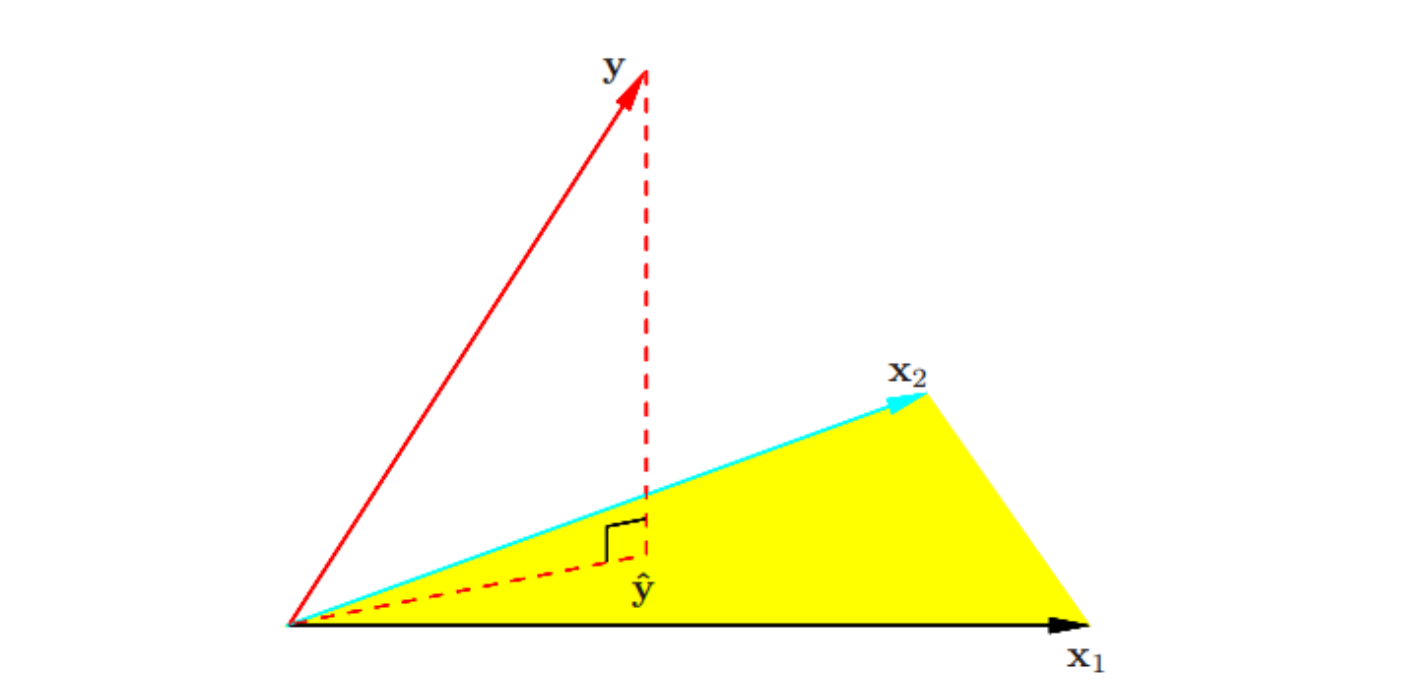
- 此时,,则称帽子矩阵,同时他也是到子空间的投影矩阵
-
当的并不是列满秩时,是奇异的,因此不唯一
- 但是同理,仍旧是在子空间中的投影
- 只不过,用 的列向量来表示这种投射的方式不止一种,但这并不代表投影有多个
- 当一个或多个定性输入用一种冗余的方式编码时经常出现非满秩的情形.通过重编码或去除 中冗余的列等方式可以解决非唯一表示的问题
2.3 参数的显著性检验¶
-
什么是显著性检验:
-
显著性,又称统计显著性(Statistical significance), 是指零假设为真的情况下拒绝零假设所要承担的风险水平,又叫概率水平
-
显著性水平:在原假设是真实的情况下,犯错的概率是一个固定的值,称为显著性水平, 而又叫置信水平
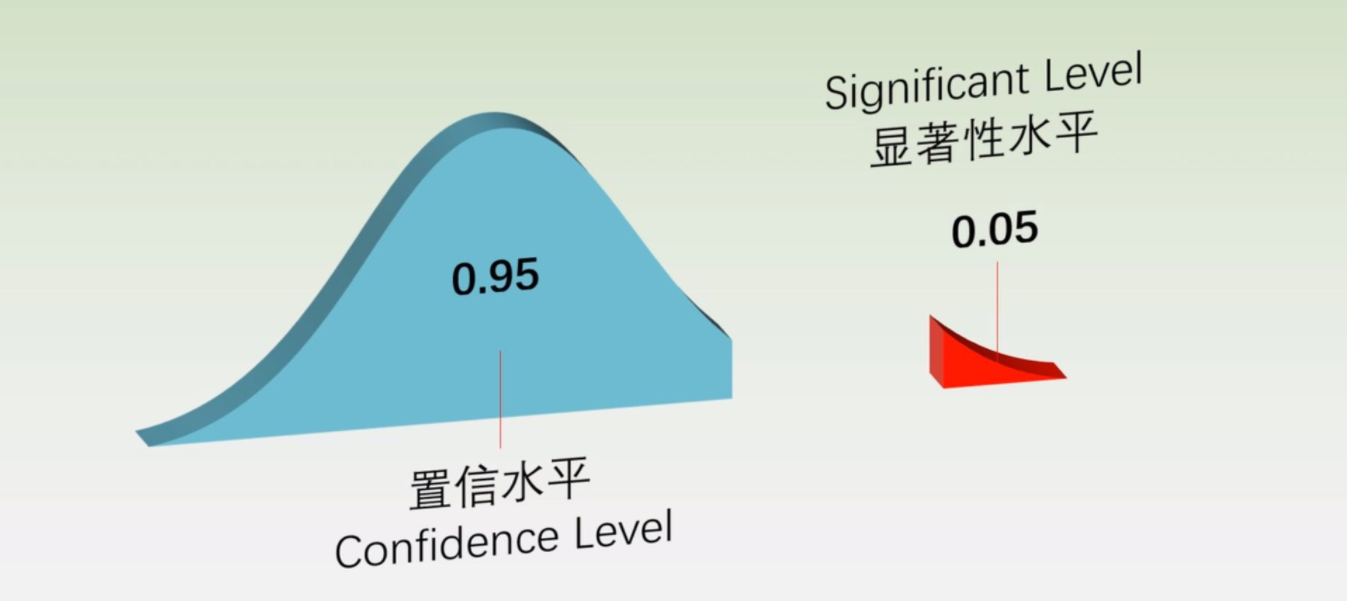
-
:发生某个时间的概率,一般认为就是小概率发生事件,就可以拒绝原建设
-
一些假设:
-
高斯-马尔可夫假设(Gauss-Markov):为了约束 的取样特点,我们现在假设观测值 不相关,且有固定的方差 ,并且 是固定的(非随机)
-
假设是线性的,因此是正确的模型
-
假设 与其期望的偏差是可加的且是正态的 其中
-
的无偏估计和分布
-
公式:
-
无偏性:使得估计是无偏估计,即
-
证明:
- 首先化简
-
定理:列满秩左乘不改变秩,行满秩右乘不改变秩(设列满秩,行满秩)
-
因此
-
由于
-
定理:若, 就有
-
由于, 所以
-
定理:若, 则的特征值一定是0或者1
-
由于是,所以的特征值只能是0或者1
-
又因为对称,可以进行特征值分解
-
因此
-
由于正态分布可加性,的每一行都符合正态分布,且和的分布都为
-
定理:独立同分布的正态变量经过正交变换仍保持独立
由于正态变量独立和不相关是等价的,所以只需要证明 $$ Cov(U_{i,:}^T\epsilon,U_{j,:}^T\epsilon) =E(U_{i,:}^T\epsilon U_{j,:}^T\epsilon)-E(U_{i,:}^T\epsilon)E(U_{j,:}^T\epsilon)
\ =E(\sum_{k=1}^{N}\sum_{l=1}^NU_{ik}U_{jl}\epsilon_{k}\epsilon_{j})-\sum_{k=1}^N E(U_{ik}\epsilon_k)\sum_{l=1}^N E(U_{jl}\epsilon_l) \ = \sum_{k=1}^{N}\sum_{l=1}^NE( U_{ik}U_{jl}\epsilon_{k}\epsilon_{j})-\sum_{k=1}^N\sum_{l=1}^N E(U_{ik}\epsilon_k) E(U_{jl}\epsilon_l) \ = \sum_{k=1}^N\sum_{l=1}^{k-1} E(U_{ik}\epsilon_kU_{jl}\epsilon_l)+\sum_{k=1}^N\sum_{l=k+1}^{N} E(U_{ik}\epsilon_kU_{jl}\epsilon_l)+E(\sum_{k=1}^NU_{ik}U_{jk}\epsilon_k^2) \-(\sum_{k=1}^N\sum_{l=1}^{k-1} E(U_{ik}\epsilon_k)E(U_{jl}\epsilon_l)+\sum_{k=1}^N\sum_{l=k+1}^{N} E(U_{ik}\epsilon_k)E(U_{jl}\epsilon_l)+\sum_{k=1}^NU_{ik}U_{jk}E(\epsilon_k)^2) = 0 \ $$
事实上,若, 是正则矩阵,则有
-
因此,互相独立,且
-
因此
-
分布、期望与协方差
-
公式
-
证明(TODO):
-
根据最小二乘公式
-
定理1:若, 且列满秩,则 证明,可由公式 得证
-
定理2(目前不对):是的仿射变换(且列满秩),那也服从多元正态分布
-
证明
-
的分布
-
由于是的矩阵变换,所以 也服从多元正态分布
-
期望
-
协方差 所以
-
当让本足够大时,即使没有Gauss-Markov条件, 也服从多元正态分布(中心极限定理)
-
-
显著性检验
-
单系数显著性检验
-
变量:
-
:第个对角元
-
:的第个元素
-
零假设:假设
-
正态统计量检验(但是没有)
-
t统计量检验(TODO:证明和的独立性)
-
事实上N足够大的时候,分布和正态
-
-
多系数显著性检验
-
举例:检验有 个水平的分类变量是否要从模型中排除,我们需要检验用来表示水平的虚拟变量的系数是否可以全部设为 0
-
假设:有个变量均为0
-
F检验统计量 是有 个参数的大模型的最小二乘法拟合的残差平方和, 是有 参数的小模型的最小二乘法拟合的残差平方和,其有 个参数约束为 0,
-
解释:
假设个参数都是0(对应的变量不显著),那么模型是只有个参数的线性模型,因此
- 小模型服从分布(关于个参数是线性的)
- 模型服从分布(关于个参数是线性的)
-
但是因为两者用同一个, 所以不独立,因此必须按照其他方式计算
-
证明:
-
首先证明
-
假设:设有个变量是约束为0
-
对模型有
-
设矩阵, 有
-
则最小化可以表述为
-
使用拉格朗日乘子法
-
求解可得
-
对有
-
对有
-
因此有
-
则
-
-
由于, 则有
-
-
置信区间
-
单参数置信区间
- 由于
- 有的置信区间为 其中是分布或者正态分布的分位数
- 多参数置信集
- 定理:, 是的概率密度函数,则 证明: 根据换元公式,有 则有 同理
- 定理:服从标准正态分布
- 定理:服从自由度为(维度)的卡方分布
- 因此,置信集为
2.4 Guass-Markov 定理¶
-
定理:若Guass-Markov假设成立,那么参数 的最小二乘估计在所有的线性无偏估计中有最小的方差
-
说明约束为无偏估计不是明智的选择,这个结论导致我们考虑本章中像岭回归的有偏估计
-
无偏性证明(假设线性模型是正确的)
-
定理形式化:若存在其他无偏估计,即,则
-
证明
- 首先证明
-
的方差可以表示为
-
的方差可以表示为
-
则
-
其他的形式化定义
-
前置定义:矩阵当且仅当半正定
-
定义:若是最小二乘估计的协方差矩阵,是其他线性无偏估计的协方差矩阵,则必有
-
证明:
-
方差偏差分析
-
考虑在输入 处的新的响应变量
-
考虑的估计值的预测误差
-
可以看到
- Gauss-Markov 定理表明最小二乘估计在所有无偏线性估计中有最小的均方误差。然而,或许存在有较小均方误差的有偏估计。这样的估计用小的偏差来换取方差大幅度的降低。实际中也会经常使用有偏估计。任何收缩或者将最小二乘的一些参数设为 0 的方法都可能导致有偏估计,例如
- 岭回归
- 变量子集选择
- 预测误差的估计值和均方误差只有常数值 的差别,表示了新观测 的方差.
2.5 的正交化(从单变量到多重变量)¶
-
单变量模型(无截距)
-
可以求出
-
可以发现,即和正交,这个过程也成为在上回归,或者说由校正(adjusted),或者关于正交化
-
多重线性回归模型
-
若的列向量相互正交,则容易得到
-
当输入变量为正交的,对模型中其它的参数估计没有影响(只对有影响)
-
几何意义:
- 在正交基子空间下的投影坐标,在每个基的坐标通过当个基就可以确定
- 这也表明,如果列向量是正交的,可以通过单独对上回归 (或者说关于正交化),来确定每个系数
-
举例:
-
假设我们有一个截距和单输入 .则 的最小二乘系数有如下形式 可以这样计算
-
才开始,的列空间有
-
让关于正交化,得到
-
此时得到的正交列空间为
-
让关于正交化,得到
-
-
正交化的几何意义
-
对正交化,并不会改变列空间,而是简单的产生一个正交基表示空间
-
在上文的例子中,正交输入的最小二乘回归.向量 在向量 上回归,得到残差向量 。 在上的回归给出 的系数。把 在 和 上的投影加起来给出了最小二乘拟合
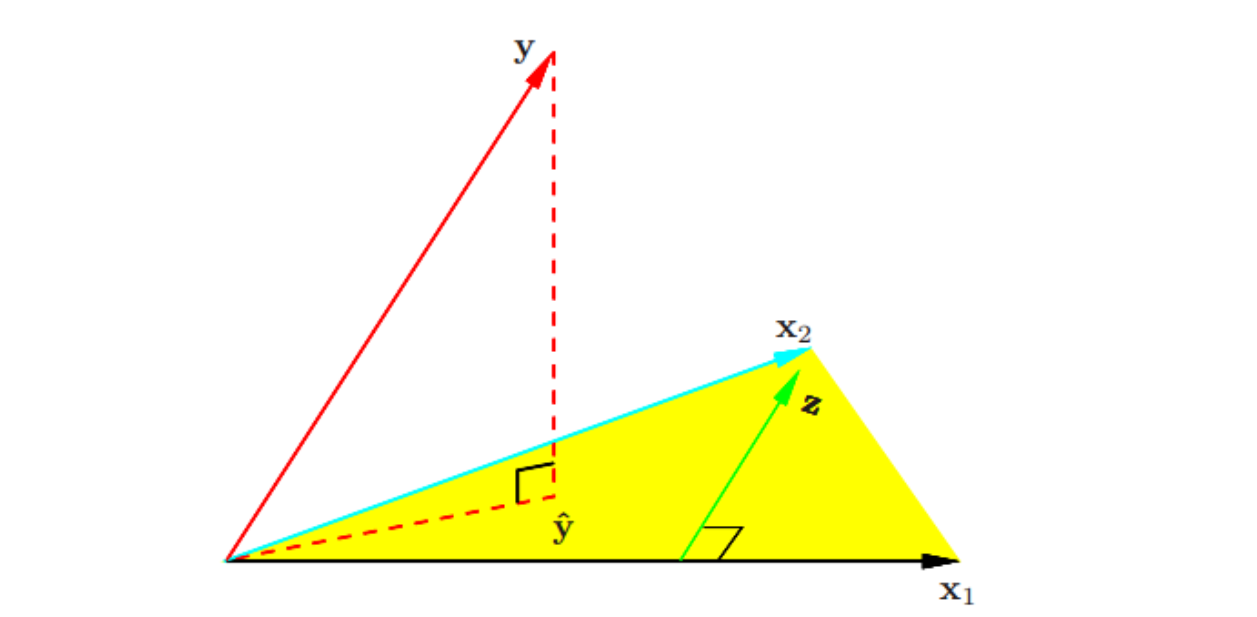
-
多重回归的 施密特(Gram-Schmidt)正交化
-
算法流程:

-
算法结果
-
算法解释
-
对于每个,对正交基组成的进行投影
-
由于是正交基,只需要分别投影,得到对投影系数为
-
减去这个投影,形成,与形成新的正交基
-
当正交化完毕后,形成正交基,因此可以分别求对的正交化
-
最后,由于和的系数是1,也就是只和有1倍的关系,所以 是的系数,也同时是的系数
-
通过反推(见习题3.4),可以求出所有的
-
-
通过对的重新排列,任何一个都可以成为最后一个,然后得到类似的结果。因此一把里说,多重回归的第个系数就是在单变量回归,是在正交化后的残差向量
-
估计参数方差 这是一个计算估计的有用的数值策略
-
矩阵形式和分解
-
对施密特算法的第二部可以写成
-
然后引入第个对角元的对角矩阵
-
其中是的正交矩阵,是的上三角矩阵
-
可以通过下式来求解和 由于是上三角矩阵,所以很容易求解,见习题3.4
-
2.6 多重输出¶
-
公式:假设有多重输出 ,我们希望通过输入变量 去预测。我们假设对于每一个输出变量有线性模型
-
矩阵形式:
-
是矩阵,是矩阵,是 的系数矩阵,是的误差矩阵
-
最小二乘估计 因此第 个输出的系数恰恰是 在 上回归的最小二乘估计.多重输出不影响其他的最小二乘估计
-
多重变量加权准则:若误差 相关,且,则更恰当的方式是修正
-
(TODO: 没懂)由多变量高斯定理自然得出
- 我的解释
- 可以看作是采样后的结果
- 是符合的的采样结果,也就是相互独立的
- 因此,加权后的可以看作,做了的新空间中,共个独立同分布的变量采样后的结果的平方和
- 在新空间仍然满足误差的独立性,因此可以用不加权的方法去做
- 解:仍然是原来的形式,具体可见习题 Ex3.11