线性判别分析¶
1 类别密度¶
-
已知目标是求最优分类的类别后验概率
-
设是的的类别密度, 也就是类别为在空间中的概率;并且还已知是类别的先验概率有, 则根据先验和后验公式,可以得到后验概率和类别密度的关系
-
由此可见,直到类别密度基本等于知道后验概率
2 线性判别分析推导¶
-
假设类别密度符合高斯分布,且其协方差矩阵是相同的
-
则比较两个类别后验概率的即可 可以看到,分类边界是一个超平面,所有的判别边界都是线性的
-
一个例子
-
下左图是, 也有三个类别的例子
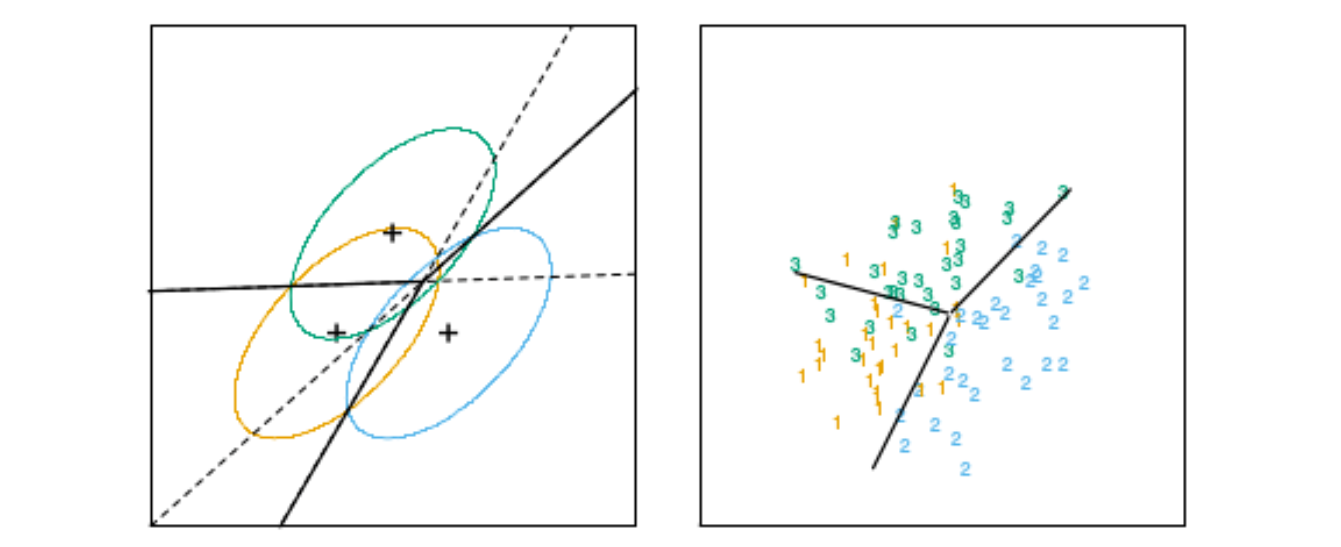
- 左图是三个协方差相同的高斯分布每个类别 95% 可能性的等高线,图中画出了线性边界
- 右图是使用了每个类别的30个样本点进行拟合后的LDA判别边界
-
根据, 可以看出线性判别函数为 如果有先验概率相等且协方差矩阵为, 则判别函数可以化简为 判别规则即
-
参数估计:高斯分布的参数是不可知的,需要使用训练数据去估计
-
-
-
- 无偏性证明
根据协方差估计-对预测变量的估计,有 于是,有 因此有
-
两个类别下的 LDA 方向
-
在两个类别的情况下,将估计参数带入, 可以得到满足下列判定条件时,分给第2类
-
可以看到,相当于方向向量,而就是通过在方向向量的投影,进行判断类别的
-
两个类别的情况下在线性判别分析和线性最小二乘之间有一个简单的对应,若将两个类别分别编码为,则最小二乘的系数向量与方向成比例,具体证明见习题 Ex 4.2
-
当多余两个类别时,LDA 与类别指示矩阵的线性回归不是一样的,且避免了跟这个方法有关的掩藏问题
3 平方判别函数¶
-
若没有假设相等, 则变为
-
因此得到了 QDA 平方判别函数
-
对类别对, 其判别边界为
-
与高维空间LDA比较
-
图像
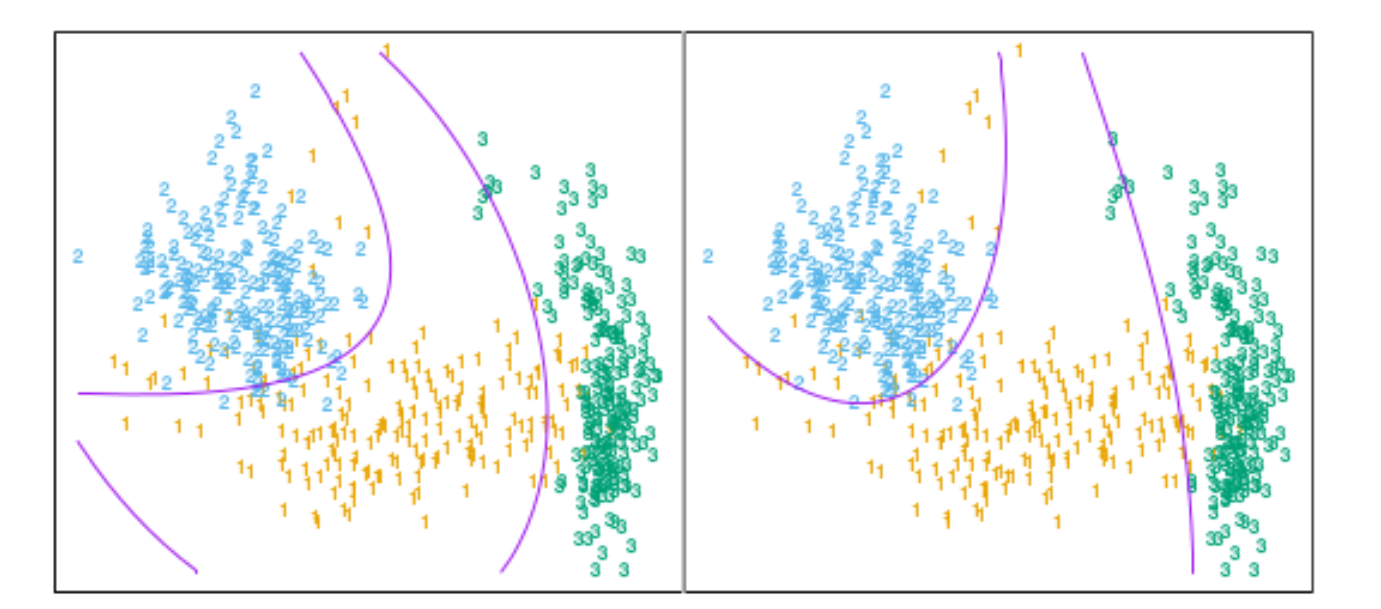
-
上图中,左边是LDA在增广空间运用 LDA 得到的,右侧是QDA
-
参数个数
-
对于 QDA,协方差矩阵必须要按每一类来估计,这意味着参数个数有显著增长。假设判断第个类别的边界(共类)
-
则LDA需要的系数参数个数为
-
则QDA需要的系数参数个数为
-
-
LDA 和 QDA 表现好的原因
-
在众多问题上表现好的原因并不是数据近似服从高斯分布,对于 LDA 协方差矩阵也不可能近似相等。很可能的一个原因是数据仅仅可以支持简单的判别边界比如线性和二次,并且通过高斯模型给出的估计是稳定的,这是一个偏差与方差之间的权衡——我们可以忍受线性判别边界的偏差因为它可以通过用比其它方法更低的方差来弥补
4 正则化判别分析¶
-
概念: LDA 和 QDA 之间的一个权衡,使得 QDA 的协方差阵向 LDA 中的共同协方差阵收缩 可以基于在验证数据的表现上进行选择,或者通过交叉验证
-
误差曲线:
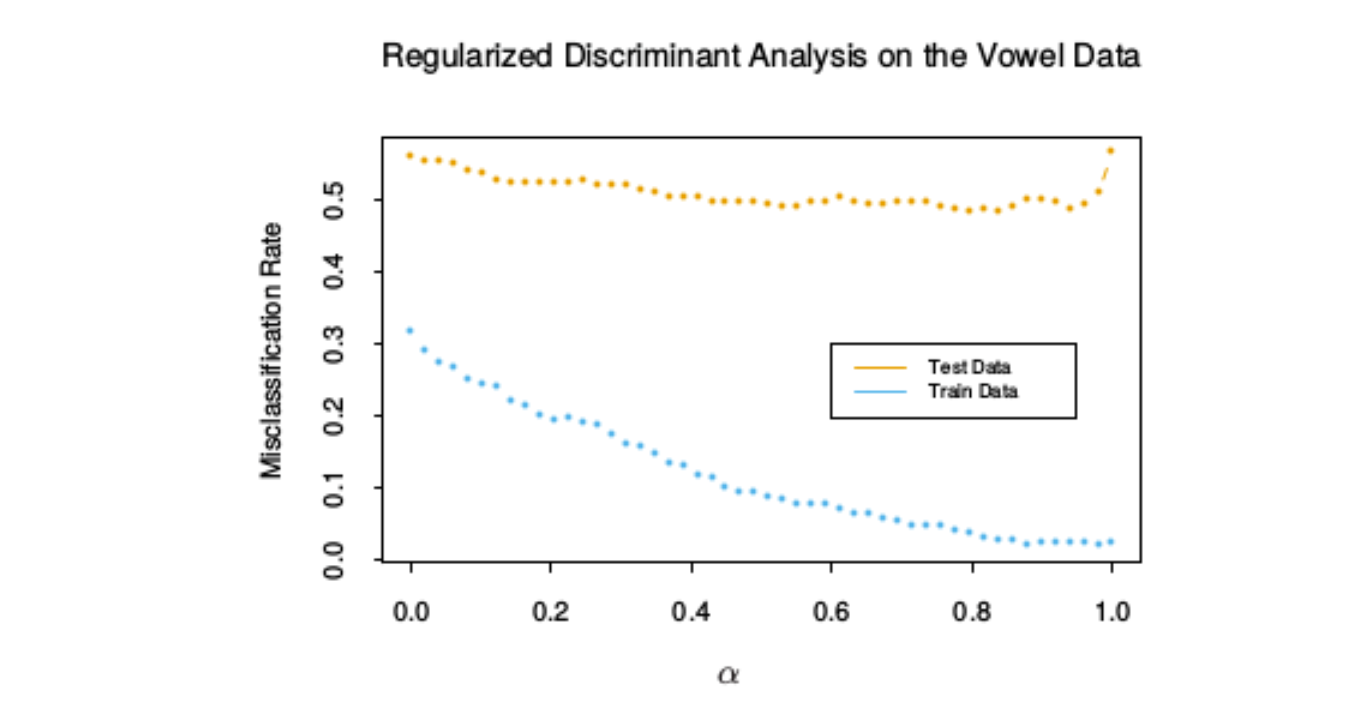
- 在 0.9 左右,测试误差达到最低,此时和二次判别分析很接近。
-
二次判别分析使得参数变多,模型更复杂,更容易发生过拟合,而LDA项起到正则化的作用
-
对修改
-
将 项标量协方差收缩,可以得到
-
是一个一般的协方差阵族
5 LDA 和 QDA 计算¶
-
LDA 和 QDA 的判别函数(均以 表示)为
-
对进行特征值分解
-
则判别函数表示为(是的第个对角元)
-
因此 LDA 的计算步骤可以写为
-
关于进行球面化(其实是标准化)
球面化的含义(标准化后的新变量服从协方差矩阵为的正态分布):

-
在 LDA 中,根据到形心的距离,并且考虑先验概率影响, 进行判断其属于第几类,即判断下列公式
6 降维线性判别分析¶
6.1 为什么要降维¶
-
若在维输入空间的个形心,其一定位于维数的子空间内,当比大得多,维数会有显著降低
-
在确定某个所属形心的时候,可以忽略到子空间的垂直距离,这是因为可以分解为两部分 由于对于不同的, 对来说是相同的, 则只需要比较在形心张成子空间投影到不同类别形心的距离(这里已经经过Section 5 中的变化了,只需要判断距离即可)
-
距离:当, 则可以在二维图中观察数据,且不会丢失任何 LDA 分类信息
-
示意图
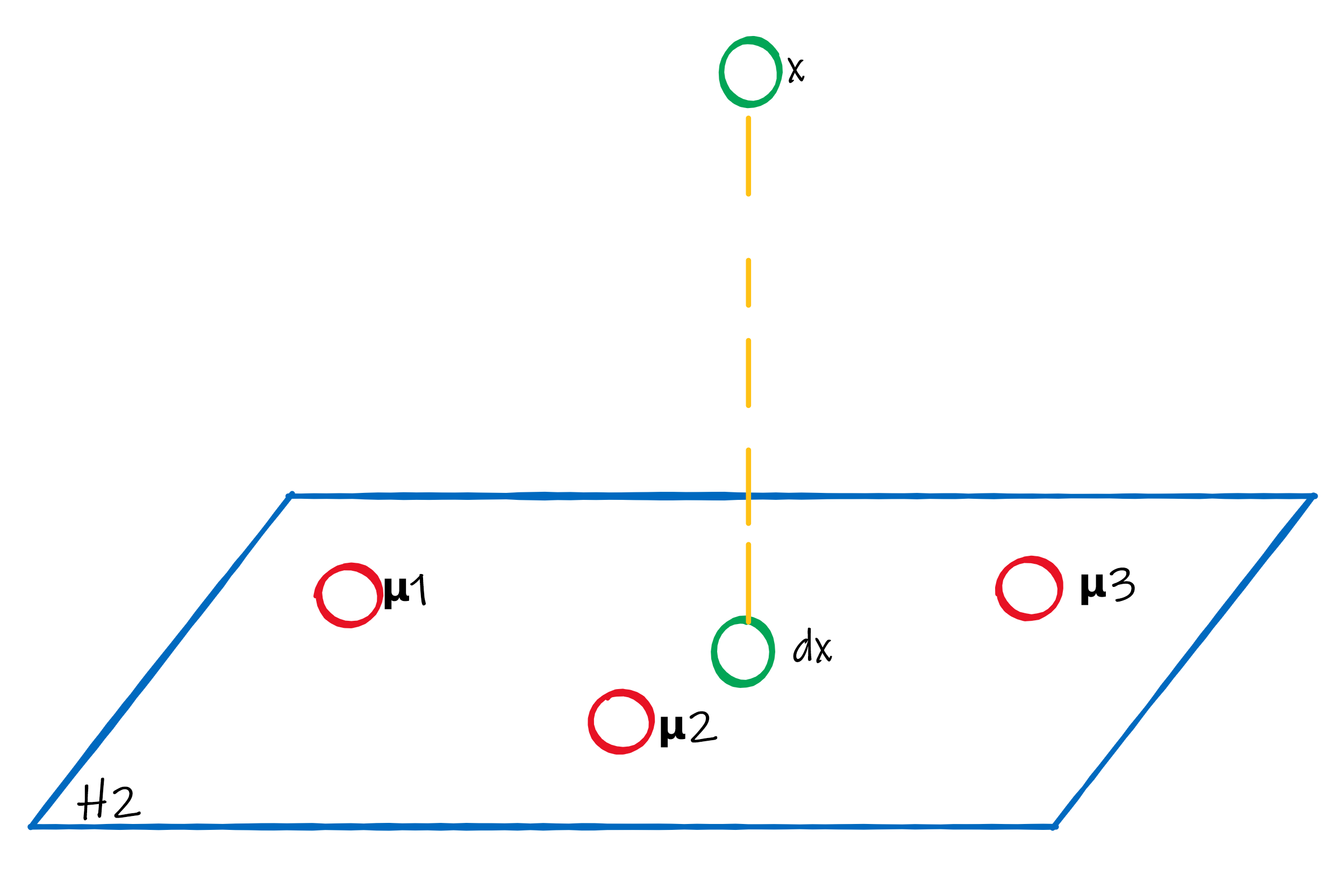
-
在上图中,是的投影,并且有三个形心, 且其都在张成子空间中
- 到的距离大小关系,与到是一致的