正则化¶
1 正则化的一般形式¶
2 来源推导¶
2.1 基于约束条件的最优化¶
-
根据VC维分析,个数越多,VC维越大,模型越复杂。为了限制模型的复杂度,则应该限制的个数:
-
由于上面是np问题,所以使用L1或者L2范数近似 拉格朗日函数为
其中, 假设的最有解为, 则最小化拉格朗日函数,与原问题等价 这与相似
2.2 基于最大后验概率估计¶
2.2.1 L2正则化¶
-
在最大似然估计中,是假设权重是未知的参数,从而求得对数似然函数:
-
若我们对一无所知,假设, 则 令, 即可得到一般代价函数
-
若我们假设的分布已知,我们可以使用最大后验概率估计
最大后验概率估计中,则将权重看作随机变量,也具有某种分布
这里是因为是先验概率,可以分析数据获得。也是可以通过分析数据获得。
-
其他写法: 其中是先验概率,可以通过样本获得。与等价。
-
若的先验分布为 可以看到,先验高斯分布下的效果等价于再代数函数增加了
-
若的先验分布为拉普拉斯分布 可以看到,先验高斯分布下的效果等价于再代数函数增加了
3 直观理解¶
3.1 保证导数值不要过大¶
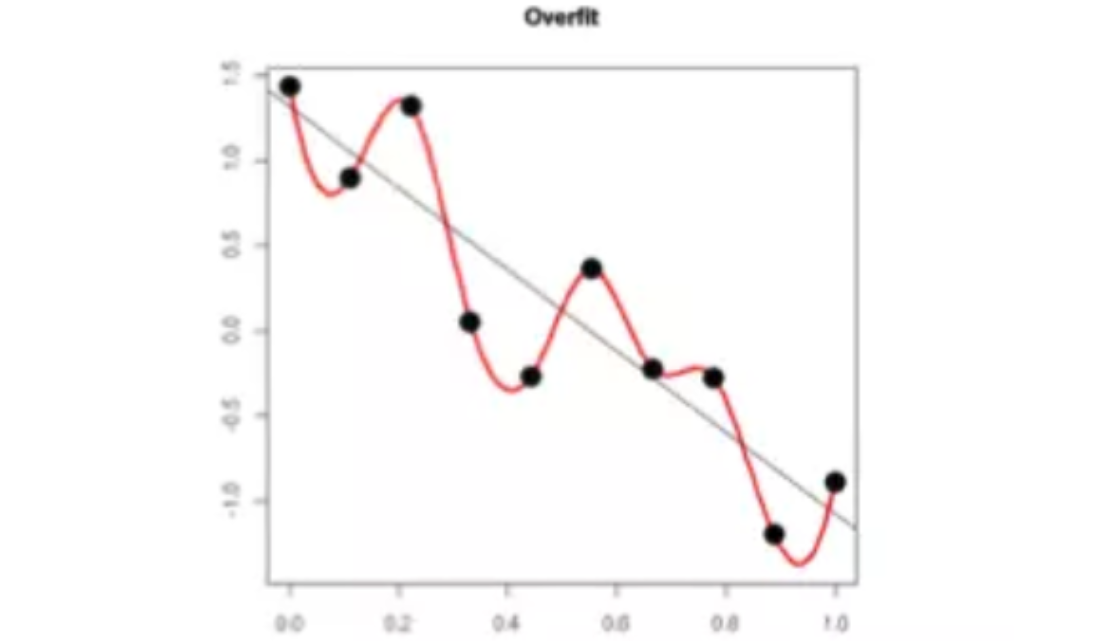
上图中,模型过于复杂是因为模型尝试去兼顾各个测试数据点, 导致模型函数如下图,处于一种动荡的状态, 每个点的到时在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。加入正则能抑制系数过大的问题。
3.2 梯度分析¶
- L2正则化
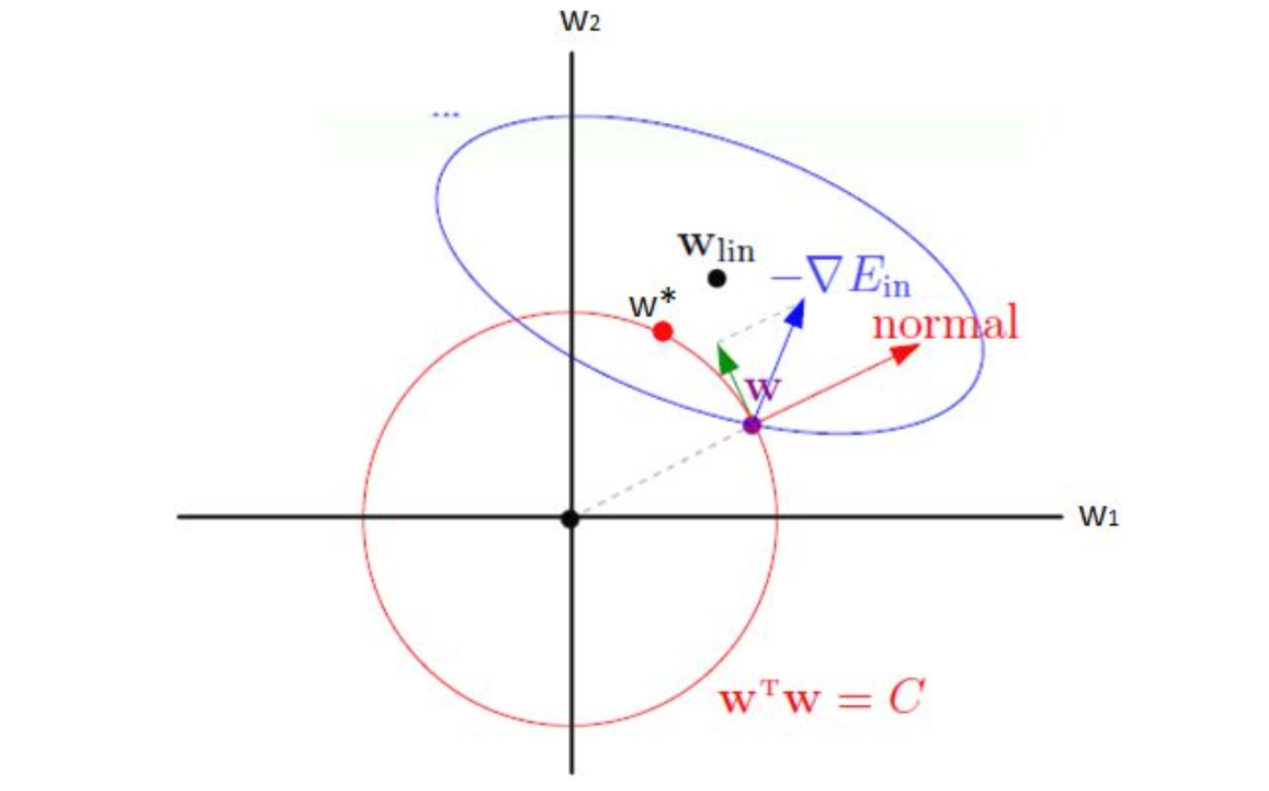
当达到最低点时,有, 此时达到最优解,也就相当于求 的极值点
- L1正则化

-
将要朝着减小的方向沿着边界移动,直到到达顶点,得到最优解, 这也是正则化产生稀疏性的原因。
-
考虑边延伸后的四边形
-
稀疏性的另一种解释
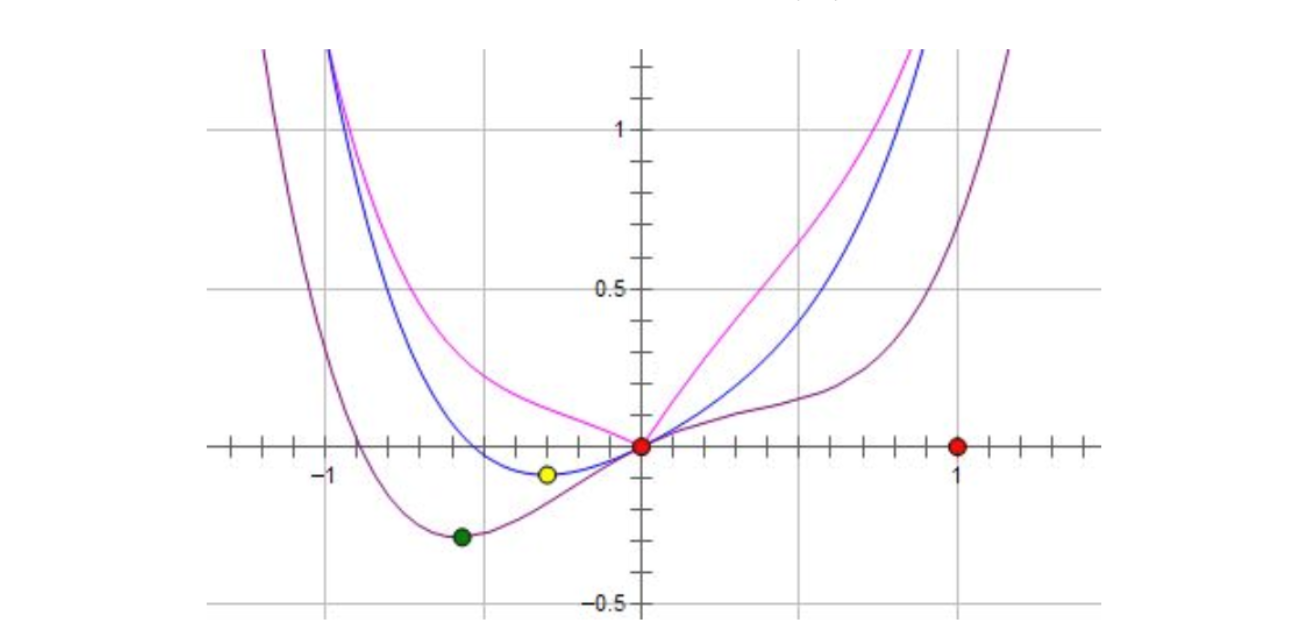
紫色时原来的函数,蓝色是的函数,粉色是的函数,可以看到施加L1 时,只要正则项的系数 C 大于原先费用函数在 0 点处的导数的绝对值, 就会变成一个极小值点。当模型发生微小改变时,最优值仍然是,这表示了其稀疏性。
3.3 稀疏性的理论分析¶
- L2正则化的非稀疏性
设是最优解,且二节可导,则进行二阶泰勒展开有 设, 设其最优解为 , 则:
由于对称,可以特征值分解为, 其中正交,且为的特征向量,则 其中为对角矩阵,对角线元素为的特征值,可以看到是在特征向量为基的空间中,第个特征向量方向缩放得到的,若, 则受到正则化影响较小。若较大,且收缩到接近于0。因为, 则正则化不会产生稀疏性的效果。
-
L1正则化的稀疏性 假设为对角阵,, 则
-
若, 则会使得最优解的某些元素是0,从而产生稀疏性
- 否则,会使得最优解便宜一个常数值
综上,L2正则化的效果是对原最优解的每个元素进行不同比例的放缩; L1 正则化则会使原最优解的元素产生不同量的偏移,并使某些元素为0,从而产生稀疏性。