变分自编码器 VAE¶
1 概念¶
- 目的:变分自编码器 (Variational AutoEncoder,VAE),构建一个从隐变量 生成目标数据 的模型。其假设了服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型 ,这个模型能够将原来的概率分布映射到训练集的概率分布
- 自编码器(AutoEncoder)作为生成模型的劣势:

- 上图是自编码器,其把输入的图片,通过编码器编码到,然后使用解码器, 。
- 可以使用作为损失函数,这样训练好后,就蕴含了输入数据的大部分信息。
- 对于解码器,不能这个模型直接当做生成模型,在低维空间中随机生成某些向量,再喂给解码器来生成图片。
- 这是没有显性对的分布进行建模,并不知道哪些能够生成有用的图片。
- 而用于训练的数据也是有限的,只对有限的会进行响应。因为空间 十分庞大,在这个空间上随机采样不一定能得到有用的。
- 变分自编码器:显性的对的分布进行建模,给定一个简单的分布,将采样的空间缩小,使得自编码器成为一个合格的生成模型。
2 推导¶
2.1 初步想法¶
-
假设:, 将看作一个服从标准多元高斯分布的变量,多维随机变量
-
得到生成模型:可以认为数据集是由某个随机过程生成的,而是这个随机过程中的一个不可观测到的隐变量。则数据集的生成看成如下步骤:
-
根据采样出样本
- 然后根据, 从条件分布中采样出数据点
因此,对上述步骤建模
2.2 解码器¶
-
架构图:
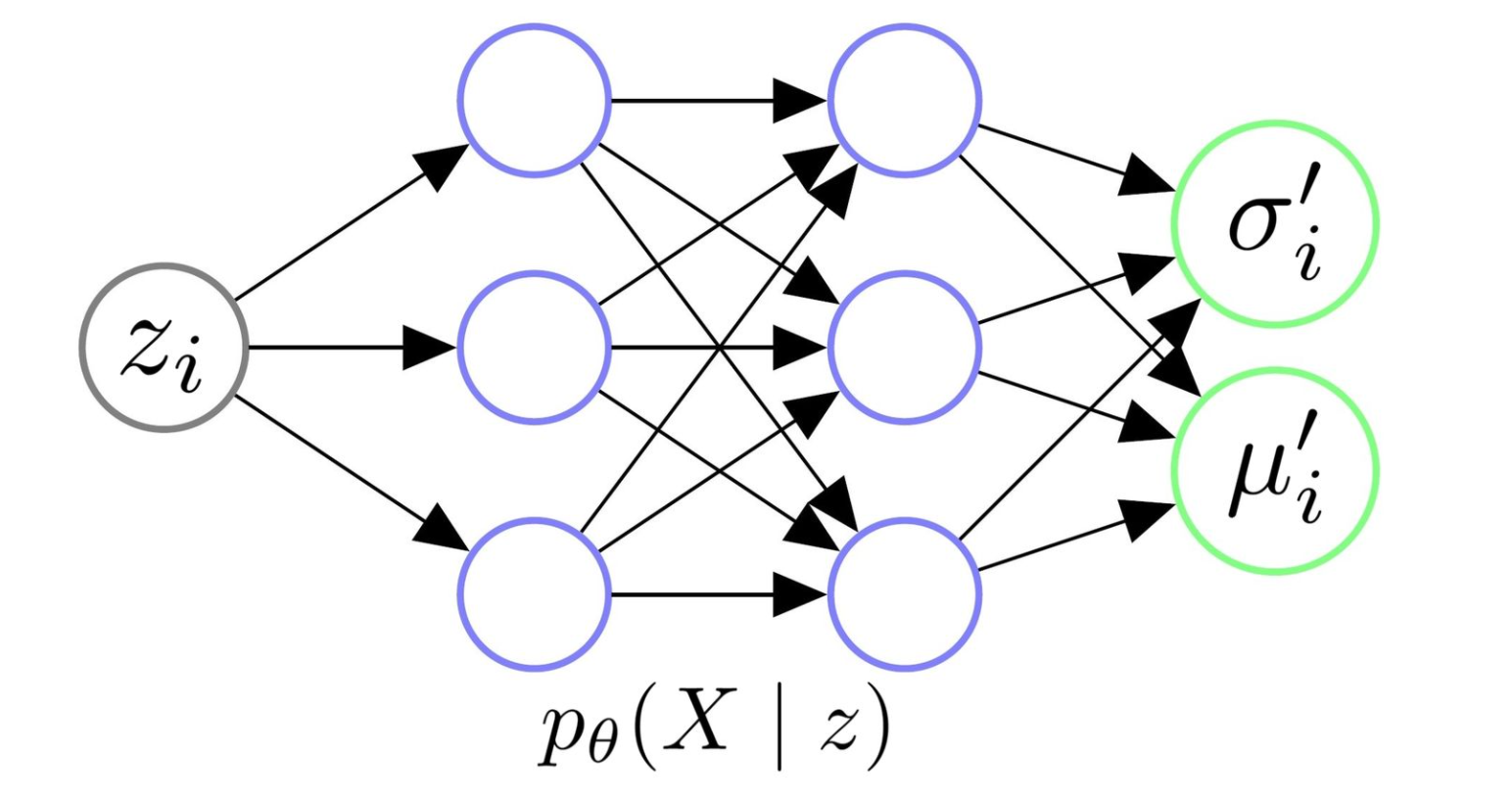
-
假设:给定后, 服从协方差为对角阵的多元高斯分布 因此,只需要输入, 让Decoder拟合出, 就可以得到分布
2.3 目标函数¶
2.3.1 统计视角下生成模型¶
- 对于生成模型,从统计视角看模板是对数据本身的分布进行建模。如果成功使用来逼近, 那k可以从中进行采样,生成一些可能的数据点
- 得到后,则使得较大的可能就是比较正常的生成对象
2.3.2 函数推导¶
-
前提:假设有数据集,且有分布。因此有:
-
极大似然估计(MLE):使用最大似然估计的思想,去优化参数
-
代价极大:
-
的维度较大,而对于, 与其强相关的是有限的。
- 如果在进行采样,需要极大量的采样。
2.4 编码器¶
- 原理:在Encoder引入后验分布。在前向传播时,把传入Encoder,并得到。从分布中进行采样后得到。之后把喂给Decoder,得到的分布。最后使用MLE去优化模型。
- 后验分布的理解:Encoder中,把先验分布用后验分布代替。
去掉(理解不太对):
之所以可以这么做,这是因为式中: 其中,是总的采样数目。是和相关的集合,是不相关的集合。可以看出,如果要最小化, 只需要考虑相关的集合部分的极值即可,也就是和强相关的那部分。
这样做的原因是为了把不同的分布分开,使得每个都可以从其相关性较大的中采样。
-
为了得到, 使用一个网络来拟合该分布
-
由于先验分布,似然分布也符合高斯分布,由贝叶斯估计中可以得到,高斯分布的共轭分布仍然是高斯分布,因此也符合高斯分布,因此可以设
-
通过Encoder进行拟合,其是一个拥有对角协方差矩阵的多元高斯分布
2.5 构架¶
- 构架图:
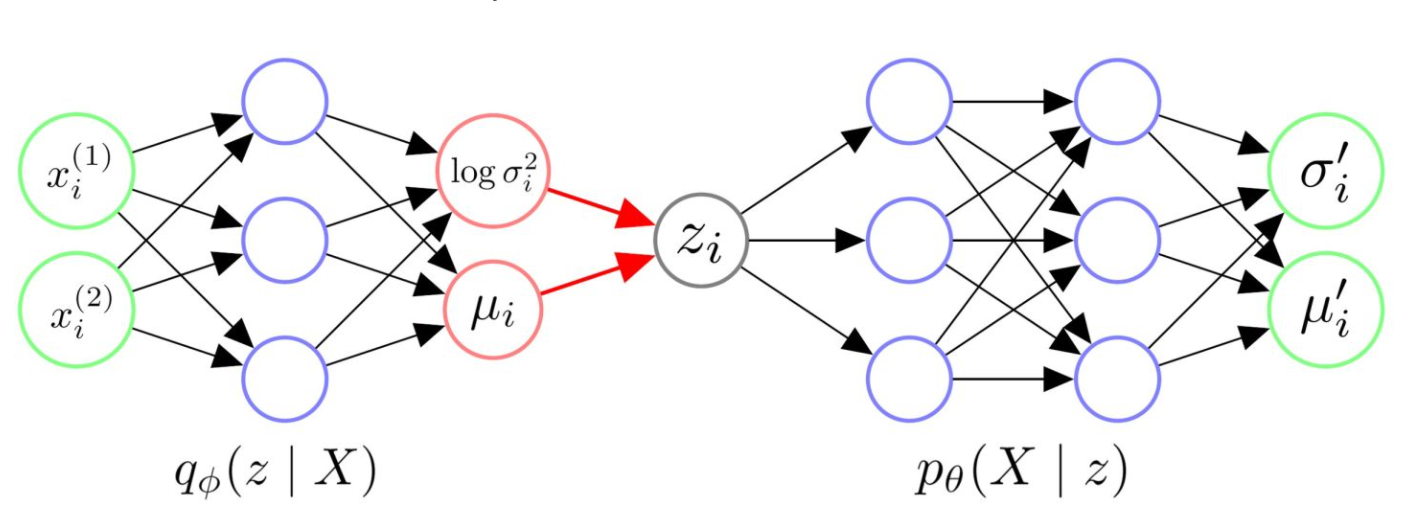
其中表示的二维特征
-
VAE 流程
-
给Encoder输入, 得到分布的均值和方差
- 从采样出, 该代表了和相似的一类样本
- 把输入到Decoder, 得到分布的均值和方向
- 从分布中进行采样,来生成可能的数据点。也可以直接拿当作数据点
NOTE: 人们一般认为的方差是固定的,因此当作超参数,而不是被Decoder进行输出
2.6 重参化技巧¶
-
构架图:
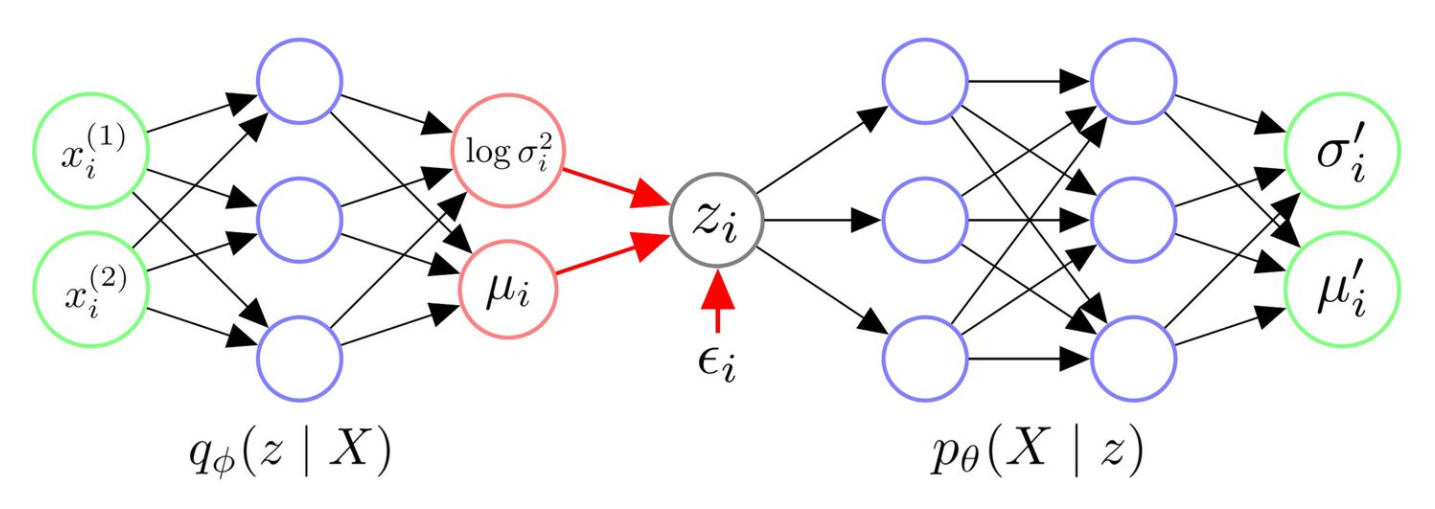
-
重参化技巧(Reparameterization Trick):
-
前向传播的第2步,调用了一个"采样函数",从采样出。这个是无法进行反向传播
-
因此,再通过Encoder得到后,然后采样,然后令,其中是Hadamard积,可以看出仍然服从正态分布。
-
这样,可以把看作是伴作一起输入到Decoder的特征
2.7 经验下限(变分下界)¶
-
经验下限被称作 ELBO (Empirical Lower Bound),通过变分法求得
-
此时最大化中的
-
其中散度, 因此是的经验下限,可以通过变分法证明了
-
对进行变换,转而求的最大值
-
只需要最大化,则被最大化的同时,被最小化
- 最大化,相当于最大似然估计
-
最小化, 相对于最小化近似后验和真实后验的差距,否则的话Encoder可能只能输出一些无意义的分布。如果没有这一项,则模型只为了使得似然概率更大,可能会使得方差为0,而加上这一项有效的避免了这种情况,保证了模型的生成能力。
-
对展开,得到
-
其中对进行计算:
-
已知:, 假设
-
因此,有
- 尝试向量运算,失败了:
-
由于各分量独立的多元正态分布,因此可以从一元导出,对于一元来说
-
因为对正态分布
-
因此有
-
拓展到协方差为对角阵的多元正态分布
-
对于,称为
- 可以在进行采样次,然后可以近似得到
- 接下来,只需要计算,前面假设了。并且假设维度是, 因此可以算出
2.8 损失函数¶
-
结合, 可以看出损失函数为 其中,是采样于,不同于前文采样于
-
之前从采样,采样出来和相关的概率很低,因此需要大量的采样
-
而上式,随着训练次数增加逼近于真实的后验分布,因此可以在有限次数的采样中采样出和关联较大的
-
在实际操作中,一般取 在前文中提到,一般把的方差当作固定超参数,当其为每一个元素均为的维向量时,得到高斯分布的情况下,VAE最终的损失函数:
-
是第个样本,表示Encoder第个输入
-
是Encoder输出,表示的参数
-
是从采样出的一个样本,是Decoder的输入
-
是Decoder的输出,表示利用解码后的
2.9 如何生成样本¶
-
在最终的 中,包含了项,其使得向靠拢。若所有的都很接近标准正态分布,那么根据定义有
-
因此,训练好VAE后,只需要在采样喂给Decoder即可生成可能得数据点
3 条件VAE(Conditional VAE)¶
- 背景:
- 在VAE中,可以在采样喂给Decoder即可生成新的数据点,但是不能控制数据点的类别。
- 然而有时候,我们需要控制数据点的类别。例如MNIST手写数字的例子,原版VAE只能采样得到后随机生成数字。然而,更多的时候我们可能会希望模型能够生成我们指定的数字
- 例如有数据集, 其中是。想通过来控制生成的结果,需要引入CVAE
- 流程:
- 原来是对建模,现在对进行建模
- 原来对进行建模,现在对进行建模
- 原来Decoder是对似然分布建模,现在需要对进行建模
- 原来Encoder对近似后验分布进行建模,现在对进行建模
- 只要对不同的, 有不同的Encoder、Decoder即可。一个直观方法就是把当作Encoder和Decoder的输入即可。