线性单元和梯度下降¶
1 线性单元概念¶
- 感知器存在的问题
感知器有一个问题,当面对的数据集不是线性可分的时候,『感知器规则』可能无法收敛,这意味着我们永远也无法完成一个感知器的训练。
- 线性单元
为了解决这个问题,我们使用一个可导的线性函数来替代感知器的阶跃函数,这种感知器就叫做线性单元。线性单元在面对线性不可分的数据集时,会收敛到一个最佳的近似上。
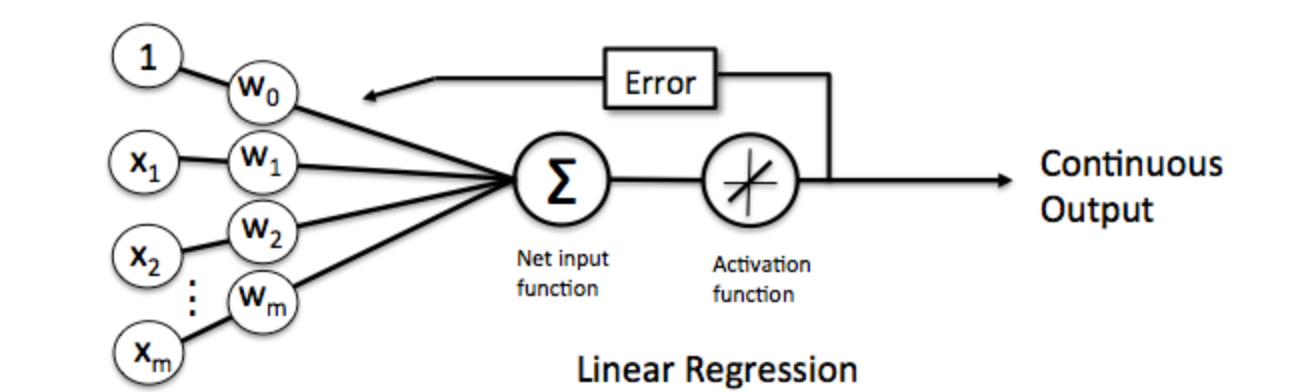
线性单元的激活函数可以简单设置为为。这样替换了激活函数之后,线性单元将返回一个实数值而不是0,1分类。因此线性单元用来解决回归问题而不是分类问题。
- 模型表达式
输出就是输入特征的线性组合。
2 目标函数¶
-
单个样本误差
-
模型的误差
-
梯度下降法优化
-
求梯度
-
梯度下降法公式 是步长,也称作学习速率。
-
随机梯度下降法
-
要遍历训练数据中所有的样本进行计算,我们称这种算法叫做批梯度下降(Batch Gradient Descent)。如果我们的样本非常大,比如数百万到数亿,那么计算量异常巨大。在SGD算法中,每次更新的迭代,只计算一个样本。这样对于一个具有数百万样本的训练数据,完成一次遍历就会对更新数百万次,效率大大提升。由于样本的噪音和随机性,每次更新并不一定按照减少的方向。然而,虽然存在一定随机性,大量的更新总体上沿着减少的方向前进的,因此最后也能收敛到最小值附近。

- SGD不仅仅效率高,而且随机性有时候反而是好事。今天的目标函数是一个『凸函数』,沿着梯度反方向就能找到全局唯一的最小值。然而对于非凸函数来说,存在许多局部最小值。随机性有助于我们逃离某些很糟糕的局部最小值,从而获得一个更好的模型。