长短时记忆网络¶
1 RNN的缺点¶
- 因此可能发生梯度消失或者梯度爆炸。
2 长短时记忆网络概念¶
-
由于梯度消失,原始RNN无法处理长距离依赖。
-
原始RNN的隐藏层只有一个状态,即,它对于短期的输入非常敏感。那么,假如我们再增加一个状态,即,让它来保存长期的状态。新增加的状态c,称为单元状态(cell state)。

- 展开后

- LSTM的关键,就是怎样控制长期状态c。在这里,LSTM的思路是使用三个控制开关。第一个开关,负责控制继续保存长期状态c,第二个开关,负责控制把即时状态输入到长期状态c,第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出。
3 LSTM前向计算¶
-
门(gate)的概念:门实际上就是一层全连接层,它的输入是一个向量,输出是一个0到1之间的实数向量。假设是门的权重向量,是偏置项 门的输出是0到1之间的实数向量,那么,当门输出为0时,任何向量与之相乘都会得到0向量,这就相当于啥都不能通过;输出为1时,任何向量与之相乘都不会有任何改变,这就相当于啥都可以通过。因为的值域为, 所以门的状态都是半开半闭的。
-
LSTM用两个门来控制单元状态c的内容:
- 遗忘门:它决定了上一时刻的单元状态有多少保留到当前时刻
- 输入门:他决定当前时刻网络输入有多少保存到单元状态
-
LSTM用输出门(output gate)来控制单元状态有多少输出到LSTM的当前输出值。
-
公式
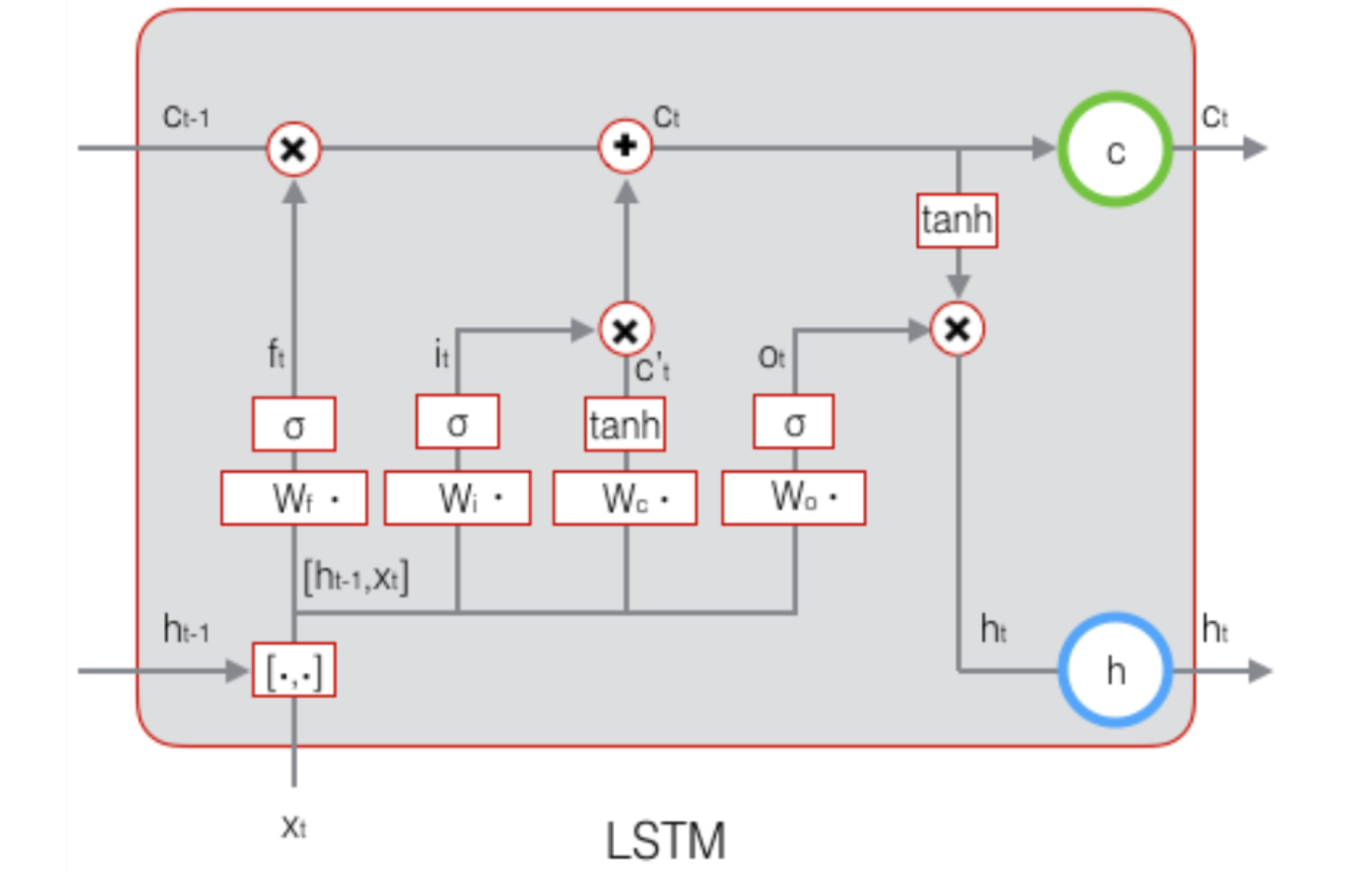
- 遗忘门:
是遗忘门的权重矩阵,是向量拼接,是遗忘门的偏置项,是函数。若输入维度是, 隐藏层维度是, 单元状态的维度是, 则可以分别为
-
输入门:
-
计算用于描述当前输入的候选单元状态
-
单元状态 我们就把LSTM关于当前的记忆和长期的记忆组合在一起,形成了新的单元状态。
-
输出门
-
最终输出
4 GRU分析¶
-
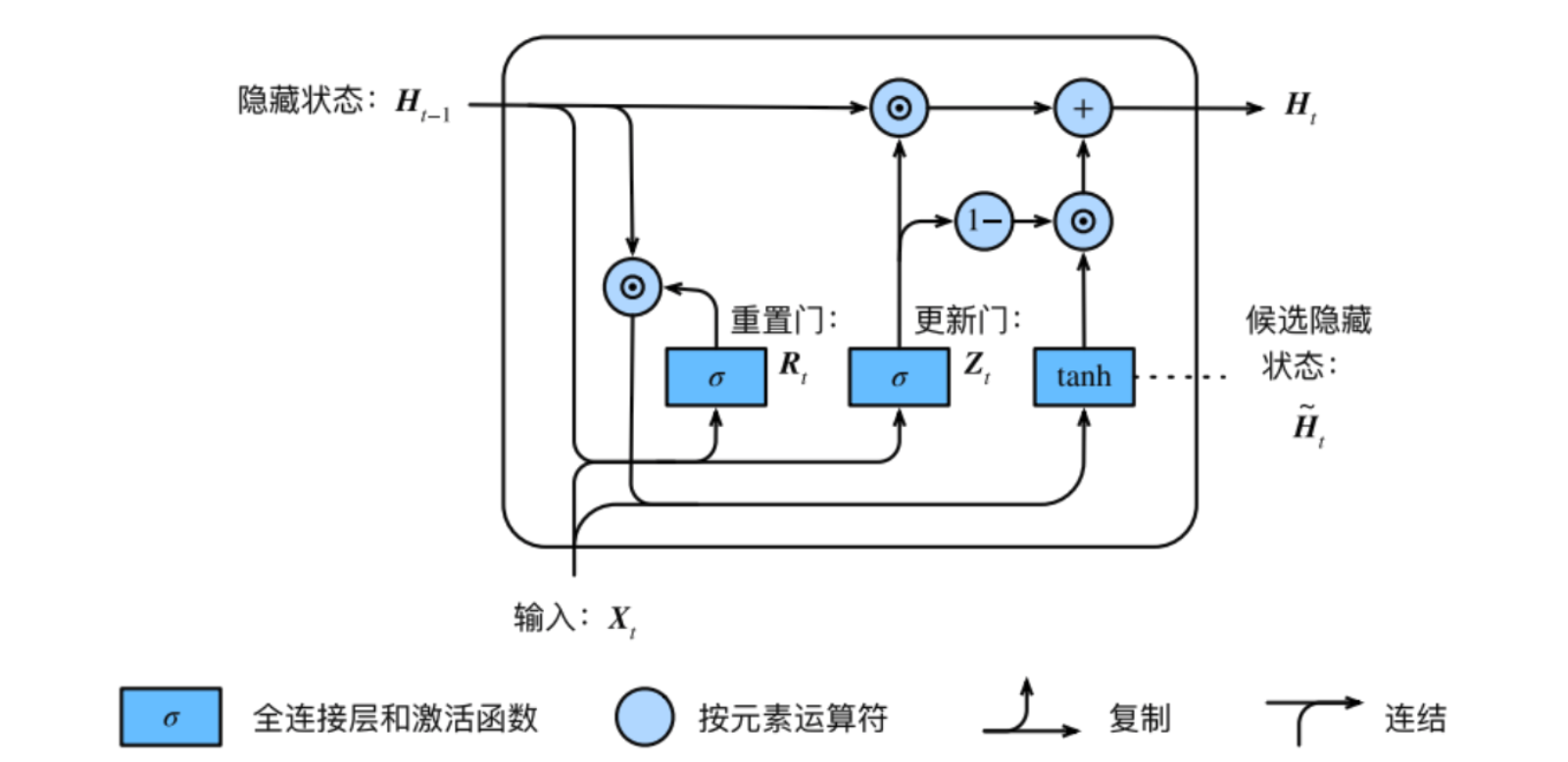
门控循环神经⽹络:GRU它引⼊了重置门(reset gate)和更新门(update gate)的概念,从而修改了循环神经⽹络中隐藏状态的计算⽅式。
-
结构图
-
重置门:
-
更新门:
-
候选隐藏状态
-
隐藏状态
-
分析
-
使用一个门控就同时进行了遗忘和选择记忆
- , 相当于遗忘门
- ,这里包含了对的选择性记忆
-
可以看到,这里的遗忘和选择是联动的。也就是说,对于传递进来的维度信息,我们会进行选择性遗忘,则遗忘了多少权重 ,我们就会使用包含当前输入的中所对应的权重进行弥补 。
-
如果在一段时间内近似于1,则输入信息几乎没有流入,则保留较早时刻的状态。
- 更新⻔有助于捕捉时间序列⾥⻓期的依赖关系
- 重置⻔有助于捕捉时间序列⾥短期的依赖关系
5 LSTM的训练¶
5.1 训练框架¶
- 前向计算每个神经元的输出值
-
反向计算每个神经元的误差项
-
根据误差项,计算权重的梯度
5.2 公式符号说明¶
-
-
-
设在时刻,LSTM的输出值为, 则我们定义时刻的误差项为 我们这里假设误差项是损失函数对输出值的导数,而不是对加权输入的导数。这是因为LSTM有四个加权输入,我们希望往上一层传递一个误差项而不是四个。对加权输入的误差项定义如下:
5.3 误差项沿时间的反向传递¶
- 沿时间反向传递误差项,就是要计算出t-1时刻的误差项。
- 求 $$ o_t = \sigma(net_{o,t})\ do_t= \sigma'(net_{o,t})\odot dnet_{o,t} = diag(\sigma(net_{o,t})(1-\sigma(net_{o,t})))^Tdnet_{o,t}\ \frac{\partial o_t}{\partial net_{o,t}} = diag[(\sigma(net_{o,t})\odot(1-\sigma(net_{o,t}))]\=diag[o_t\odot(1-o_t)]\ \frac{\partial f_t}{\partial net_{f,t}}=diag[f_t\odot(1-f_t)]\ \frac{\partial i_t}{\partial net_{i,t}}=diag[i_t\odot(1-i_t)]\ d\overline c_t = \tanh'(net_{\overline c_t})\odot dnet_{\overline c_t,t} = diag[1-\tanh(net_{\overline c_t})^2]^Tdnet_{\overline c_t,t}\ \frac{\partial \overline c_t}{\partial net_{i,t}}=diag[1-\overline c_t^2]\ dh_t = do_t \odot \tanh(c_t)+o_t \odot \tanh'(c_t)\odot dc_t \ = diag[\tanh(c_t)]^T do_t + diag[o_t\odot (1-\tanh(c_t)^2)]^Tdc_t \ dc_t = df_t\odot c_{t-1} + di_t\odot \overline c_t + i_t\odot d\overline c_t \ = diag[c_{t-1}]^Tdf_t+diag[\overline c_t]^Tdi_t+diag[i_t]^Td\overline c_t\ \delta_{o,t} = \frac{\partial o_t}{net_{o,t}}\frac{\partial h_t}{\partial o_t}\delta_t = diag[o_t\odot(1-o_t)] diag[\tanh(c_t)]\delta_t\ \delta_{f,t} = \frac{\partial f_t}{net_{f,t}}\frac{\partial c_t}{\partial f_t}\frac{\partial h_t}{\partial c_t}\delta_t = diag[f_t\odot(1-f_t)] diag[c_{t-1}]diag[o_t\odot (1-\tanh(c_t)^2)]\delta_t\
\delta_{i,t} = \frac{\partial i_t}{net_{i,t}}\frac{\partial c_t}{\partial i_t}\frac{\partial h_t}{\partial c_t}\delta_t = diag[i_t\odot(1-i_t)] diag[\overline c_{t}]diag[o_t\odot (1-\tanh(c_t)^2)]\delta_t\ \delta_{\overline c,t} = \frac{\partial \overline c_t}{net_{\overline c,t}}\frac{\partial c_t}{\partial \overline c_t}\frac{\partial h_t}{\partial c_t}\delta_t = diag[1-\overline c_t^2]diag[i_t]diag[o_t\odot (1-\tanh(c_t)^2)]\delta_t $$
- 与 的关系
5.4 将误差项传递到上一层¶
-
假设当前为第l层,定义l-1层的误差项是误差函数对l-1层加权输入的导数
-
问题:函数应该怎么得到?
5.5 权重梯度的计算¶
-
对于的权重梯度,我们知道它的梯度是各个时刻梯度之和。我们首先求出它们在t时刻的梯度,然后再求出他们最终的梯度。
-
对于的权重梯度,它的梯度也是各个时刻梯度之和。
-
对于, 只需要直接计算