Lasso 和相关路径算法的补充¶
1 概述¶
- LAR 算法提出,许多研究都在发展对于不同问题的正则化拟合算法,这部分是一些相关的想法和以 LAR 算法为先驱的其它路径算法
2 增长的向前逐渐回归¶
-
概念:这是 向前逐渐回归 (forward-stagewise regression) (参考向前逐渐回归)的增长版本,称为 增长的向前逐渐回归 (Incremental Forward Stagewise Regression), 这是一种类似 LAR 的算法,又称
-
过程:

-
假设都经过标准化,均值为0
-
定义为当前的相关系数
-
选择相关系数绝对值最大的变量,并且向概变量移动一个小变量
-
若, 其就是向前逐渐回归了
-
系数路径
-
图像

- 以前列腺癌为例
- 左侧, 右侧。
-
在这种情形下与 lasso 路径相同。这个极限过程为 无穷小的向前逐渐回归 (infinitesimal forward stagewise regression) ,或者
- 其与 LAR 算法均允许每个连结变量 (tied predictor) 以一种平衡的方式更新他们的系数,并且在相关性方面保持连结
- 但是 LAR 在这些连结预测变量中的最小二乘拟合可以导致系数向相反的方向移动到它们的相关系数,因此需要对 LAR 算法进行修正
-
LAR 关于 的修正
-
在 LAR 算法的第 4 步(见LAR 算法)中,系数朝着联合最小二乘方向移动,注意此时方向与最小二乘方向可能一致或者相反。这是因为LAR这里相关性相同指的是相关系数绝对值相同,所以系数增长方向能是相反的
-
然而 中的移动方向始终与最小二乘方向保持一致
-
因此对 LAR 算法的第 4 步修正如下

- 这个修正相当于一个非负的最小二乘拟合, 保持系数的符号与相关系数的符号一致
- 这样的路径也可以通过计算出来
-
-
对于 LAR 算法来说
- 若各个系数均是单调不减或者单调不增, 则LAR, lasso, 的路径是一致的
- 若各个系数均不过, 则LAR 的 lasso是一致的
-
和lasso对比
-
比lasso 约束更强,可以看成lasso 的单调版本,其系数曲线更光滑,所以有更小的方差(TODO: 不理解光滑和小方差)
-
比lasso 更加复杂
-
lasso 是 以范数为方向,进行单位增正后,最优化达到的残差平方和
-
是 在沿着系数路径弧长为方向,进行单位增长后,最优化达到的残差平方和。这是因为的系数不会轻易改变方向,所以范数就是弧长
弧长( arc length):对可到曲线的弧长为, 对于分段函数(LAR函数曲线来说,其系数弧长就是各个段系数范数变换的和。
-
3 分段线性路径算法¶
-
对于问题 其中损失函数和惩罚函数都是凸函数
-
该问题解的路径 为分段线性的充分条件为(这也意味着解的路径可以有效地计算出来)
- 关于 的函数是二次或者分段二次
-
关于 分段线性
-
例子:
-
损失函数平方损失,和绝对误差损失
-
损失函数为Huber loss(支持向量机的例子)
- 图像(这里的就是)

- 在习题 SLS Ex 2.11 讨论了Huber loss和 正则化的等价性, 其优点是能增强平方误差损失函数(MSE, mean square error)对离群点的鲁棒性,对离群点的惩罚减小。
-
损失函数为Hinge loss(支持向量机的例子, 具体在后面详细讨论)
-
是用于分类器的损失函数,定义为
-
定义
-
4 Dantzig 选择器¶
-
Dantzig selector (DS)定义:下面准则的解称为 DS, 其中 是无穷范数,表示向量中绝对值最大的组分
-
lasso 和 DS
-
对于活跃集中的所有变量,lasso 保持着与当前残差相同的内积(以及相关系数),并且将它们的系数向残差平方和的最优下降方向变化.在这个过程中,相同的相关系数单调下降(习题 Ex 3.23),并且在任何时刻这个相关性大于非活跃集中的变量
- Dantzig 选择器试图最小化当前残差与所有变量之间的最大内积。因此它可以达到比 lasso 更小的最大值,但是在这一过程中会发生奇怪的现象,它可以在模型中包含这样一个变量,其与当前残差的相关性小于不在活跃集中的变量与残差的相关性。(TODO:之后看论文,这里不是特别理解)
5 The Grouped Lasso¶
-
背景:当时预测变量属于预定义的群体中, 希望对群体中每个成员一起进行收缩或选择(全要某个群体,或者全不要某个群体)
-
假设个预测变量被分到个群体中,第个群有个成员,第群的预测变量表示为, 则有下列公式
-
存在某个, 可以使得预测变量的整个群体都排除在模型外。这是因为 这一项使得某个群体中的变量系数趋于相同(要不一起收缩,要不一起不变,欧式范数为 0 当且仅当其各组分都为 0)
6 lasso 的更多性质¶
-
这领域的结果对模型矩阵假设了如下条件
-
其中是标记真实的潜在模型中非零系数特征的子集, 是其对应的特征列。是的补集,也就是系数为0的子集, 是其对应的特征列。
-
这个假设的含义为,的列在 上的最小二乘系数不会太大, 即两种变量并不是高度相关的
-
可以修改 lasso 惩罚函数使得更大的系数收缩得不要太剧烈
-
平稳削减绝对偏差法 (smoothly clipped absolute deviation, SCAD) 用 替换了, 有公式 其中第二项降低了对较大的收缩程度,当, 此时不收缩(TODO 没懂)
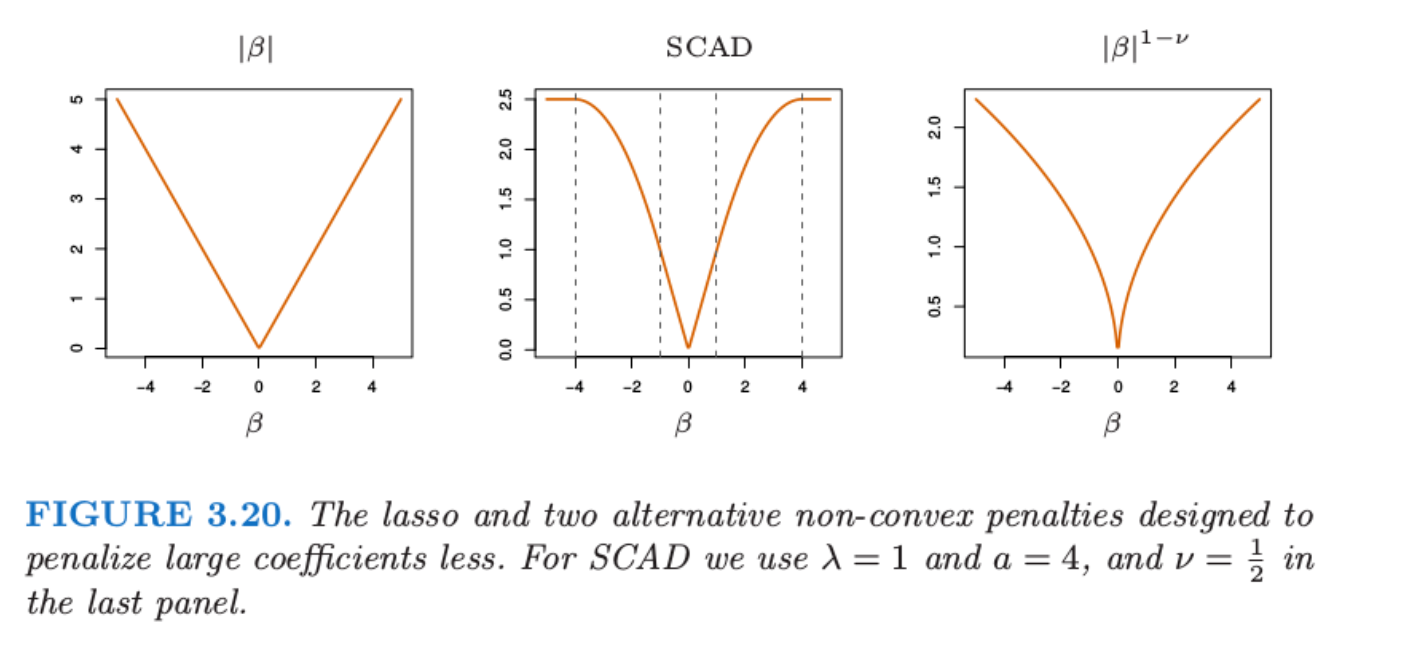
上图展示了SCAD,lasso和对降低大系数收缩程度作用,但是其使得计算变得困难(因为不是凸的
-
adaptive lasso (Zou, 2006) 采用了, 这是对(上图)的近似,但是其是凸的,就容易计算。
7 Pathwise Coordinate Optimization¶
-
简单坐标下降 (simple coordinate descent), 可以替代使用LAR计算 lasso 路径的算法 。想法是固定 Lagrangian 形式中的惩罚参数 λ,在控制其它参数固定不变时,相继地优化每一个参数
-
假设表示参数为 的的当前估计,然后要优化的参数为, 公式如下假设预测变量都经过标准化得到 0 均值和单位范数)
-
上式可以看作响应变量为部分残差, 预测变量为,系数为
-
其中,除了, 其他都是固定的,并且对 进行更新
-
这里的是在标准化变量中,部分残差对单变量的最小二乘系数
-
重复迭代,轮流考虑每个变量直到收敛,直到得到lasso估计
-
该方法可以计算每个网格节点上的 lasso 解,该算法流程如下
-
从开始,是使得的最小的
- 对进行缩小到新的节点, 得到,迭代每个变量直到收敛。
- 再次进行缩小,, 并且采用前一个解作为 新值的“warm start"。
- 不断重复该过程,该算法可能比LARS快,因为其采用 warm start, 并且只计算网格节点的解,并没有计算整个lasso路径